|
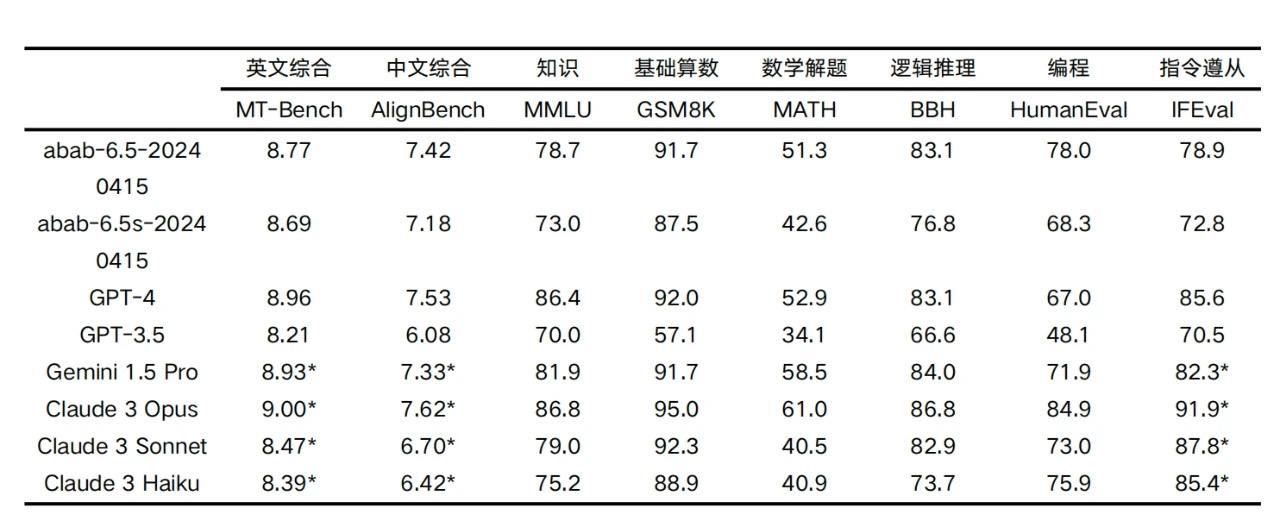
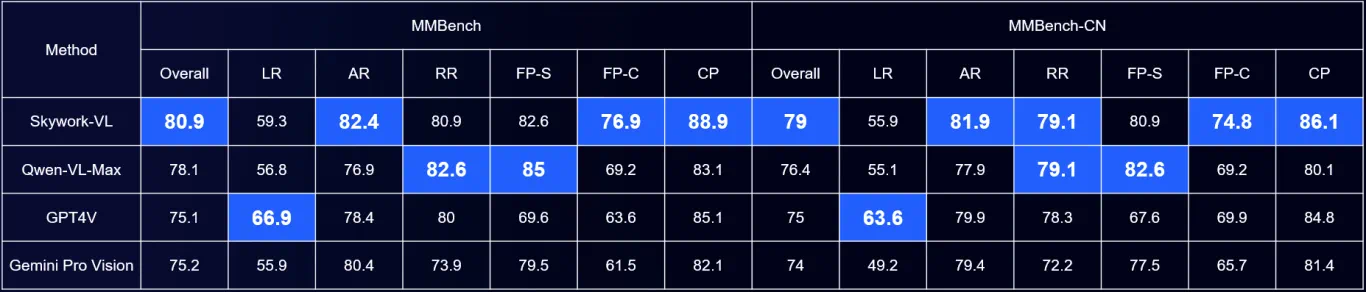
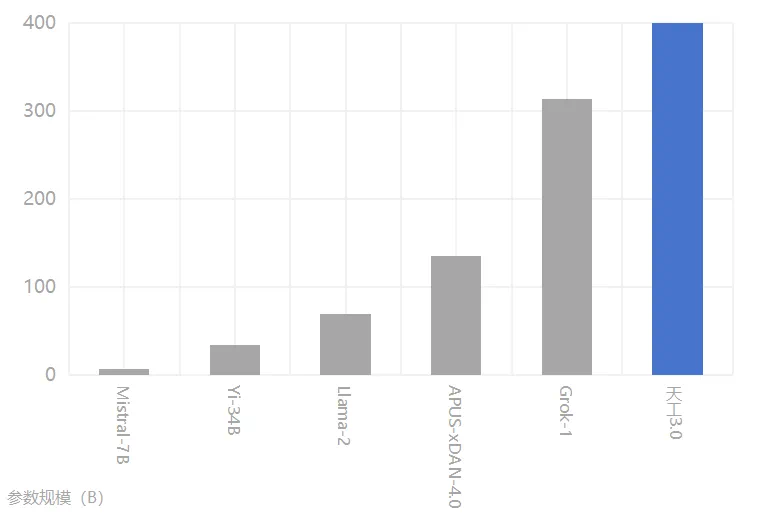
4 月 17 日,两家大模型企业相继宣布重大更新。 午间,MiniMax在其公众号宣布正式推出abab 6.5 系列模型,其中abab 6.5 包含万亿参数,支持 200k tokens的上下文长度,abab 6.5s 与 abab 6.5 使用了同样的训练技术和数据,但是更高效,支持 200k tokens 的上下文长度,可以 1 秒内处理近 3 万字的文本。 更早一点,上午昆仑万维在其官方公众号宣布,开源4000亿参数的大模型天工3.0,这超越了马斯克此前开源的3140亿参数的Grok-1,是全球最大的开源MoE(混合专家模型)大模型。昆仑万维提到,天工3.0在语义理解、逻辑推理、通用性、泛化性、不确定性知识、学习能力等领域拥有突破性的性能提升,在MMBench等多项权威多模态测评结果中,天工3.0超越GPT-4V。 来到2024年,大模型领域的“千模大战”还在继续。开源模型的参数一次比一次更大,从几百亿来到几千亿,而闭源模型也在不断沿着Scaling Laws(尺度定律)路径升级,在千亿参数的基础上攀登万亿。同时,大模型厂商也拿出了更多的应用开始落地。 有观点认为2024年会是应用爆发的一年,此前第一财经记者问及MiniMax技术副总裁安德森是否认可这一观点,他认为很有可能爆发,“今年大模型相关技术仍然会高速发展,大概率会达到难以想象的高度。” “卷”大模型 在发布模型时,按照惯例各家都会公布对标头部模型的能力分数。 MiniMax表示,各类核心能力测试中,abab 6.5开始接近 GPT-4、 Claude-3、 Gemini-1.5 等世界上最领先的大语言模型。
MiniMax在 200k token 内进行了业界常用的“大海捞针”测试,即在很长的文本中放入一个和该文本无关的句子(针),然后通过自然语言提问模型,看模型是否准确将这个“针”回答出来。MiniMax提到,在 891 次测试中,abab 6.5 均能正确回答。 昆仑万维提到,“在MMBench等多项权威多模态测评结果中,天工3.0超越GPT-4V。”相较于上一代天工2.0 MoE大模型,天工3.0模型技术知识能力提升超过20%,数学/推理/代码/文创能力提升超过30%。
天工3.0新增了搜索增强、研究模式、调用代码及绘制图表、多次调用联网搜索等能力,并针对性地训练了模型的Agent能力,能够独立完成规划、调用、组合外部工具及信息。 昆仑万维表示,天工3.0是全球首个多模态“超级模型”(Super Model),集成了AI搜索、AI写作、AI长文本阅读、AI对话、AI语音合成、AI图片生成、AI漫画创作、AI图片识别、AI音乐生成、AI代码写作、AI表格生成等多项能力,是大模型时代的“超级应用”。 对于国内大模型圈子来说,两家公司今日的更新都将大模型水平再提升了一个台阶。 在MiniMax之前,阶跃星辰是国内第一个对外公开万亿参数模型的创业公司,不过当时发布的是预览版,在3月23日的2024全球开发者先锋大会上,在发布Step-1 千亿参数语言大模型的同时,阶跃星辰创始人姜大昕对外发布了Step-2万亿参数MoE语言大模型预览版,提供 API 接口给部分合作伙伴试用。 阶跃星辰创始人姜大昕是微软前全球副总裁,在公布万亿参数模型预览版时,他提到,“要把模型做大不是一件简单的事情”。 在过去的一年,国内不下 10个模型达到了 GPT-3.5 的水平,所以业内有个观点,认为追赶 OpenAI也没有那么困难。但实际上, GPT-3.5 是一个千亿参数的模型。要达到 GPT-4 的万亿规模参数,各个维度的要求都上了一个台阶,阶跃星辰表示,“模型规模提升到万亿对算力、系统、数据和算法都提出了新要求。”业内只有极少数公司能做到。 而在开源模型参数方面,上一次破纪录的更新是在3月18日,马斯克旗下大模型公司 xAI 在官网宣布开源 3140 亿参数的大模型Grok-1,这是当时参数量最大的开源模型,此前开源大模型中影响力较大的是 Meta开源的Llama 2,有700亿参数。
范围缩小到国内,此前最大的开源模型是阿里的千问72B,有着720亿参数。就在4月2日,国内有了首个千亿参数的开源MoE模型,当天APUS与大模型创企新旦智能联手宣布开源APUS-xDAN大模型4.0,参数规模为1360亿。据APUS实测,其综合性能超过GPT-3.5,达到GPT-4的90%。 值得一提的是,APUS-xDAN大模型4.0可在消费级显卡4090上运行,这也是国内首个可以在消费级显卡上运行的千亿MoE中英文大模型。官网表示,APUS-xDAN 大模型4.0采用GPT4类似的MoE架构,特点是多专家模型组合,同时激活使用只有2个子模块,实际运行效率对比传统Dense同尺寸模型效率提升200%,推理成本下降400%。在实际部署上,通过进一步的高精度微调量化技术,模型尺寸缩小500%,从而拥有了国内首个可以在消费级显卡运行的千亿MoE中英文大模型。 MoE模型架构已经成为目前大部分大模型厂商的共识,这种架构将神经网络拆分成多个专家子网络,面对一次输入,既可以指定某一位“专家”来回答,也可以要求多位“专家”回答,甚至全部参与回答,最终依据权重综合给出结果。这使得 MoE 架构的可扩展性优秀,开发者可以在一个巨型模型上,继续增加参数量,进行横向扩展。同时因为 MoE 可以选择只启用部分专家子模型,也在保持性能的同时,降低了推理成本。 昆仑万维提到,MoE混合专家模型是全球技术最领先、性能最强大的基座模型技术路径,相较于其他模型,MoE大模型应对复杂任务能力更强、模型响应速度更快、训练及推理效率更高、可扩展性更强。 模型越大越好吗 除了MoE之外,大模型厂商们目前的另一信仰无一例外是Scaling Laws,他们坚信大力能出奇迹,要将大模型的规模做得更大。 此前阶跃星辰就表示,“攀爬 Scaling Laws 是极其艰巨但必须坚持的任务,我们正走在正确的路上。” MiniMax此次发文提到,在升级至万亿参数的过程中,找到了越来越多加速实现Scaling Laws(尺度定律)的途径,包括改进模型架构,重构数据 pipeline,训练算法及并行训练策略优化等,此次发布的 abab 6.5 和 abab 6.5s 就是加速 Scaling Laws 过程的阶段性成果。 但要攀登Scaling Laws并不容易。在万亿参数规模上,根据阶跃星辰数据,至少需要等效 A800 万卡单一集群,高效稳定的训练,十万亿tokens 高质量的数据,加上驾驭新颖的MoE 架构,任何一环出现短板,就很难将模型提升至万亿参数。 “我们就是因为充分意识到这件事情有多艰难,才判断 GPT-3.5 以后只有极少数团队有能力继续攀爬 Scaling Laws。”阶跃星辰认为攀登 Scaling Law 是一个“铁人四项”的超级工程,它包含了算力、系统、数据和算法四大要素。阶跃星辰提到,从创立初始就在四要素方面做了充分准备,包括自建机房和租用算力,团队此前实践过单集群万卡以上的系统建设与管理,在算法上团队也能驾驭万亿参数的 MoE 架构。 不过,对于大模型参数是否越大越好,业界已经开始反思。上海人工智能实验室主任助理、领军科学家乔宇此前在GDC大会上就表示,沿着Scaling Law,未来对于数据算力的需求越来越多,大家会有一个问题,Scaling Law何处是尽头,跟现在相比,大模型至少还有1-2个数量级的提升。 “到2030年,是不是我们再提高两个数量级就有机会实现真正通用的人工智能,但是我们也要考虑另外一个问题,按照目前这条技术路线,它对算力、对能耗的消耗非常巨大。我们真的需要把我们这么大的社会资源都投入到这样的领域中来,还是需要现在这种Scaling Laws更加高效的方法,后者是这个时代研究者、开发者必须思考的问题。”乔宇说。 更早前,乔宇提到,过去人工智能兴起核心的一点是大力出奇迹,堆更多的数据、用更多的算力,但只靠规模、只靠数据解决不了幻觉、可信和可控的问题。 模型参数越大,还必然面临的是成本的问题。在此前的采访中有业内人士就表示,如果每一个用户的需求都用大模型千亿参数去响应的话,企业方的成本收益也会算不过来,更不用说万亿参数的规模所面临的成本。 此前一位行业人士也提到大模型技术圈有一个现象,“去年年中时,Agent(智能体)很火,所有人都来问我有没有做Agent,好像不做我就落后于这个时代了。过了不久大家开始做MoE,有时候出席交流活动,他们就会问你这个是不是MoE的模型,就变成好像只要有了MoE这个模型就变得很先进。” 就在不久前,大模型厂商们又纷纷开始宣布长文本升级,上述行业人士认为,这个现象的意义是超越本身的技术突破的,国内所有的一线大模型机构都已经突破了兆级的长文本能力,但是不是把它作为最主要的方向去打磨,其实大家有不同的判断。 放在参数规模上,大模型最终要落地非常关键一件事是成本可控,以尽可能低的成本达到相同的效果。而大模型本身模型越大使用成本越高,绝大部分真实的应用场景或许并不需要一个超大模型来服务,大部分简单的问题相对规模小一点、成本低一点的模型就已经能解决问题,这时候,使用者可能需要考虑的是有没有必要“杀鸡用牛刀”。 |